Motionverse SDK产品介绍
V3.0 2023-6-8
一、Motionverse 简介
Motionverse是一款多模态实时驱动虚拟数字人的业务中台,主要面向有二次开发能力的行业开发者,用AI动态生成的方案,提供SDK和管理后台,解决产品和终端的虚拟数字人驱动问题。 元宇宙世界中,每个人都有自己的数字分身,也会有大量的AI数字人做为新的交互方式出现,虚拟数字人的数量将会数倍于人类的数量,传统的动作制作和动作捕捉技术方案,已经无法满足数以百亿计的动作表情需求,通过各种不同的输入情况,智能的实时的来生成所需要的动作表情和口型,这个就是Motionverse定义的多模板实时驱动解决方案。 Motionverse使用人工智能技术,利用高质量、大规模数据集,以音频源、文本源输入、传感器输入、语义输入、脚本输入等等,通过AI生成数字人的身体动作数据、面部表情数据,以及口型数据。 Motionverse做为中台产品,以API/SDK的方式,开放性的向行业提供解决方案,无论是元宇宙社区,还是新添数字人的App,或者线下大屏,VR/AR设备,只要有数字人的地方,就可以让驱动起来变得更简单,更实时,更低成本。
二、Motionverse产品能力原理
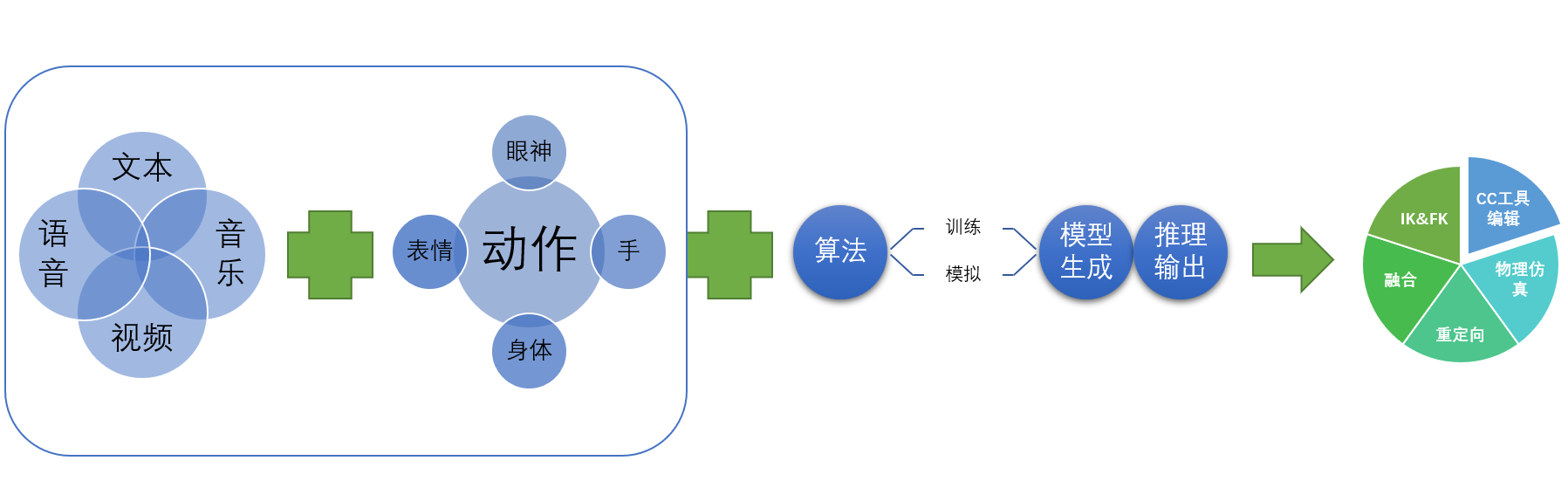
1、核心AI生成能力- 动作表情生成(Audio to Motion)
AI生成动作表情和口型,是基于机器学习的神经网络模型。这种方法不需要针对数据提取特定类型的音素,得益于神经网络的强大的函数拟合能力,可以直接将音频数据映射到表情、动作和口型中。
对于使用神经网络的方案来说,最重要的是选择合理的数据表示以及网络结构,我们使用 mesh 的方法来进行动作和表情的表示,网络结构则使用卷积神经网络。
卷积神经网络已经在计算机视觉领域证明了它提取特征的强大能力,而语音特征转换为频谱后可以用卷积神经网络来处理,用于处理语音频谱特征,较好的解决了时序信息依赖和生成模式单一的问题。
对于表情和口型来说,使用 51 个 blendershape数值来表示脸部的动作,神经网络的输出是这 51 个 blendershape 的权重,通过组合这些 blendershape 的值,可以得到脸部表情和口型合理表示。
对于身体动作来说,模型输出的是关节点的旋转,这里采用四元数来表示,在使用时,将模型输出的值按特定的顺序赋给角色骨骼即可。
多模态风格化动作数据解析和生成依赖于高质量大规模数据集,随着搭建精巧高效深度学习网络结构和不停录入训练数据,基于 transformer 架构的生成网络非常便捷高效的完成了从音频到动作、表情和口型的任务。
 2、云渲染能力
Motionverse除了大量AI能力外,因为其围绕的3D数字人领域展开服务,必不可少的提供了3D渲染相关的能力。云渲染把渲染任务提交到云端,云端的服务器会来完成渲染工作,整个渲染不占用本地的任何算力,对本地系统资源没有任何要求,还提高了工作效率,让实时渲染终究可以跨越引擎、版本以及渲染模式,随用随取,多设备、多显卡、多服务器自动分配,自动均衡。
2、云渲染能力
Motionverse除了大量AI能力外,因为其围绕的3D数字人领域展开服务,必不可少的提供了3D渲染相关的能力。云渲染把渲染任务提交到云端,云端的服务器会来完成渲染工作,整个渲染不占用本地的任何算力,对本地系统资源没有任何要求,还提高了工作效率,让实时渲染终究可以跨越引擎、版本以及渲染模式,随用随取,多设备、多显卡、多服务器自动分配,自动均衡。
三、Motionverse产品架构
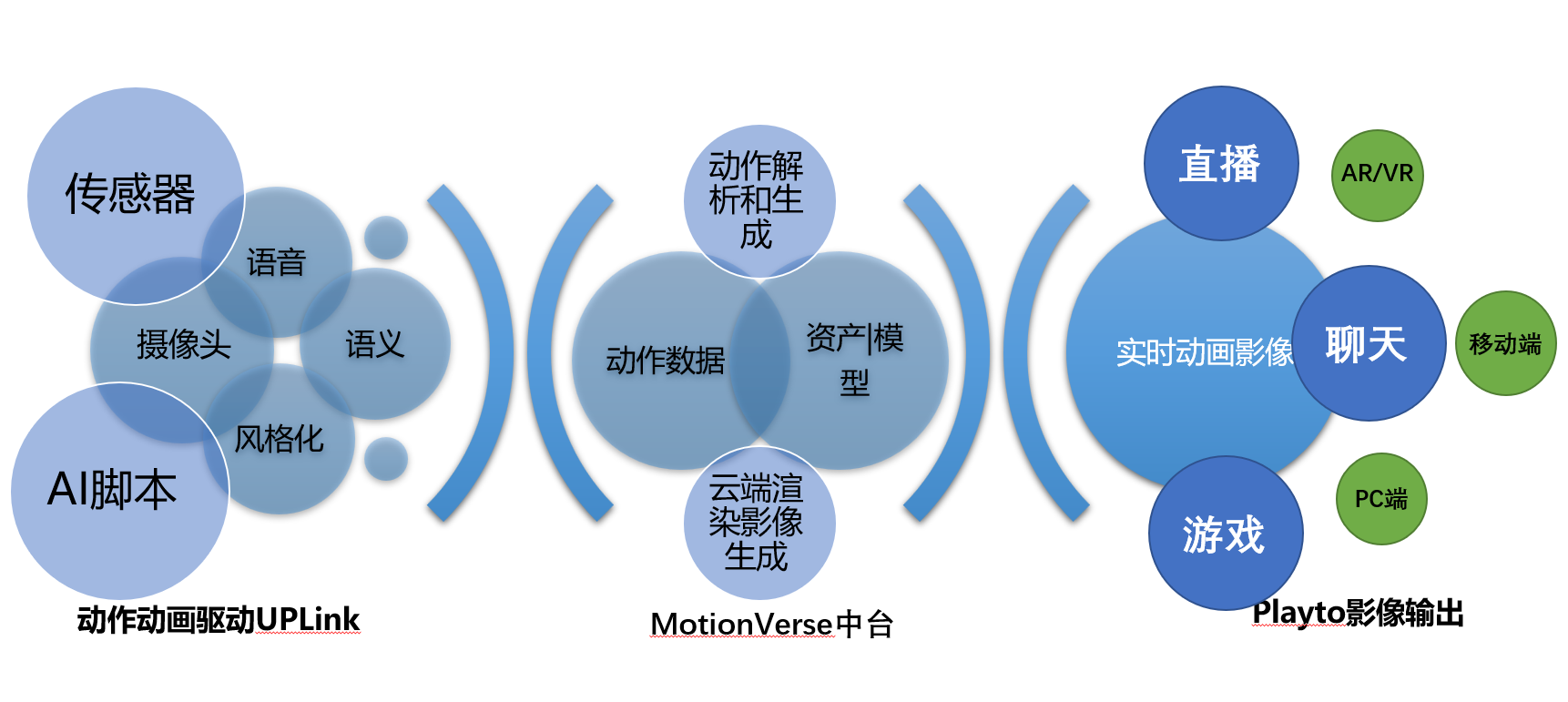 上图表述了Motionverse的产品中台结构,多模态的输入后,进入到Motionverse平台,通过AI Creator的过程,得到生成的数据,提供给各个产品和终端,用于驱动虚拟数字人。
其多模态输入方式,包含可能的各种输入,包括语音、文本、传感器、控制器、脚本等等多种方式
上图表述了Motionverse的产品中台结构,多模态的输入后,进入到Motionverse平台,通过AI Creator的过程,得到生成的数据,提供给各个产品和终端,用于驱动虚拟数字人。
其多模态输入方式,包含可能的各种输入,包括语音、文本、传感器、控制器、脚本等等多种方式
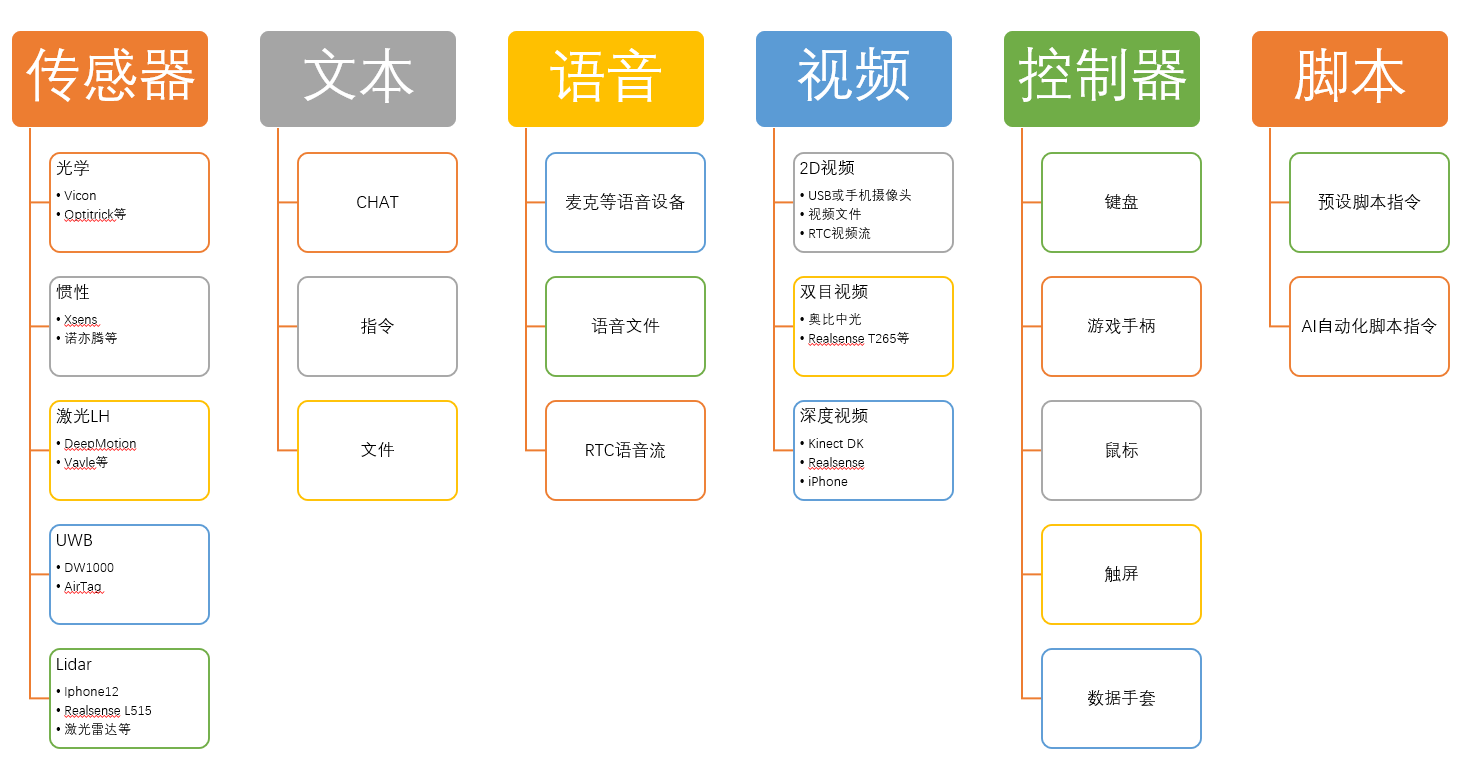 下述列举一些常见的输入到生成的使用场景
输入一段语音文件,中台生成并返回动作数据文件
通过麦克风实时输入语音,中台实时返回动作数据流
输入一段文本,中台通过AI转化合成为语音,并返回动作数据文件
通过6个传感器,输入传递头、手、脚的信息,中台生成全身的动作
通过3个传感器,输入头和手的信息,中台猜测并生成全身动作
通过输入视频文件,中台提取视频,生成动作
通过输入控制器指令,中台生成对应的动作和表情
下述列举一些常见的输入到生成的使用场景
输入一段语音文件,中台生成并返回动作数据文件
通过麦克风实时输入语音,中台实时返回动作数据流
输入一段文本,中台通过AI转化合成为语音,并返回动作数据文件
通过6个传感器,输入传递头、手、脚的信息,中台生成全身的动作
通过3个传感器,输入头和手的信息,中台猜测并生成全身动作
通过输入视频文件,中台提取视频,生成动作
通过输入控制器指令,中台生成对应的动作和表情
基于Motionverse的产品架构,通过多模态的输入信息,进行动作表情生成,结合各种数字模型,可以通过云端渲染完成最终输出。Motionverse在接收到输入后,可以完成从数据生成,到渲染相关的数字人整个工作流
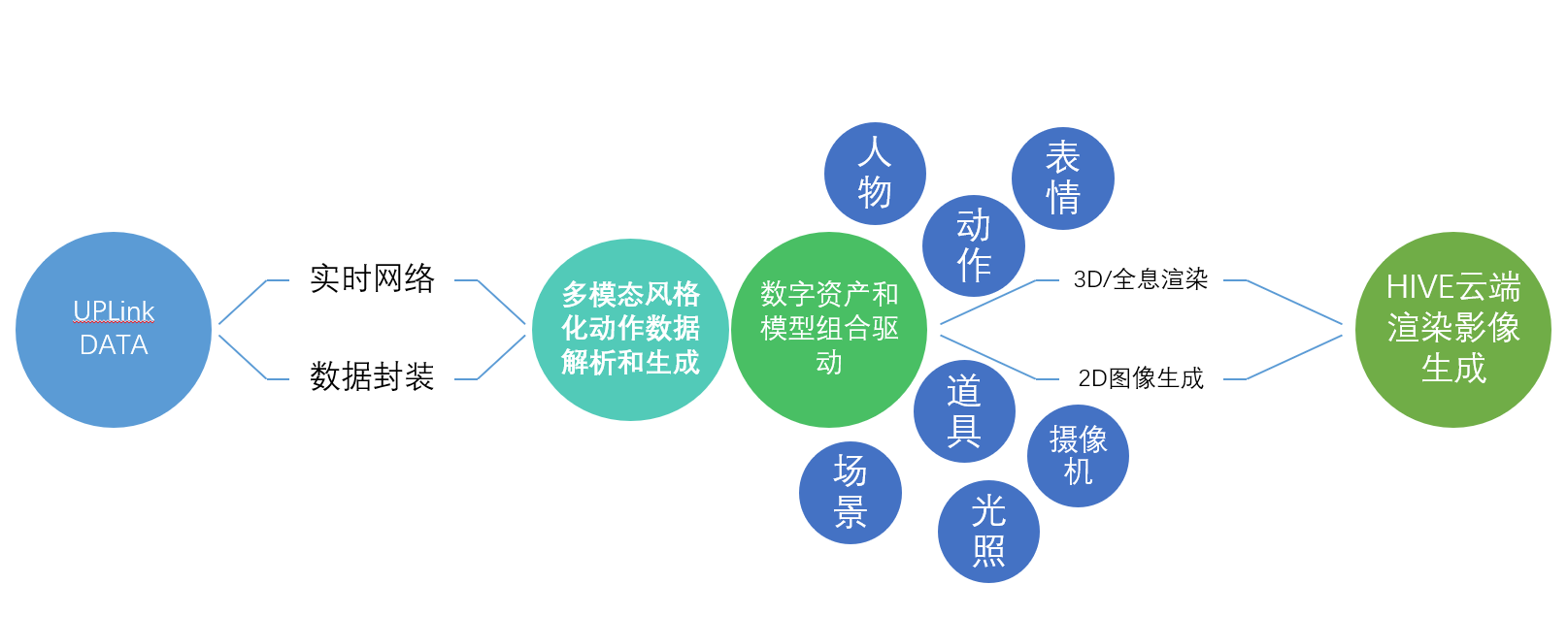
四、Motionverse四个层次的能力输出
Motionverse在接收到输入后,可以完成从数据生成,到渲染相关的数字人整个工作流。开发者可以轻松从中获取
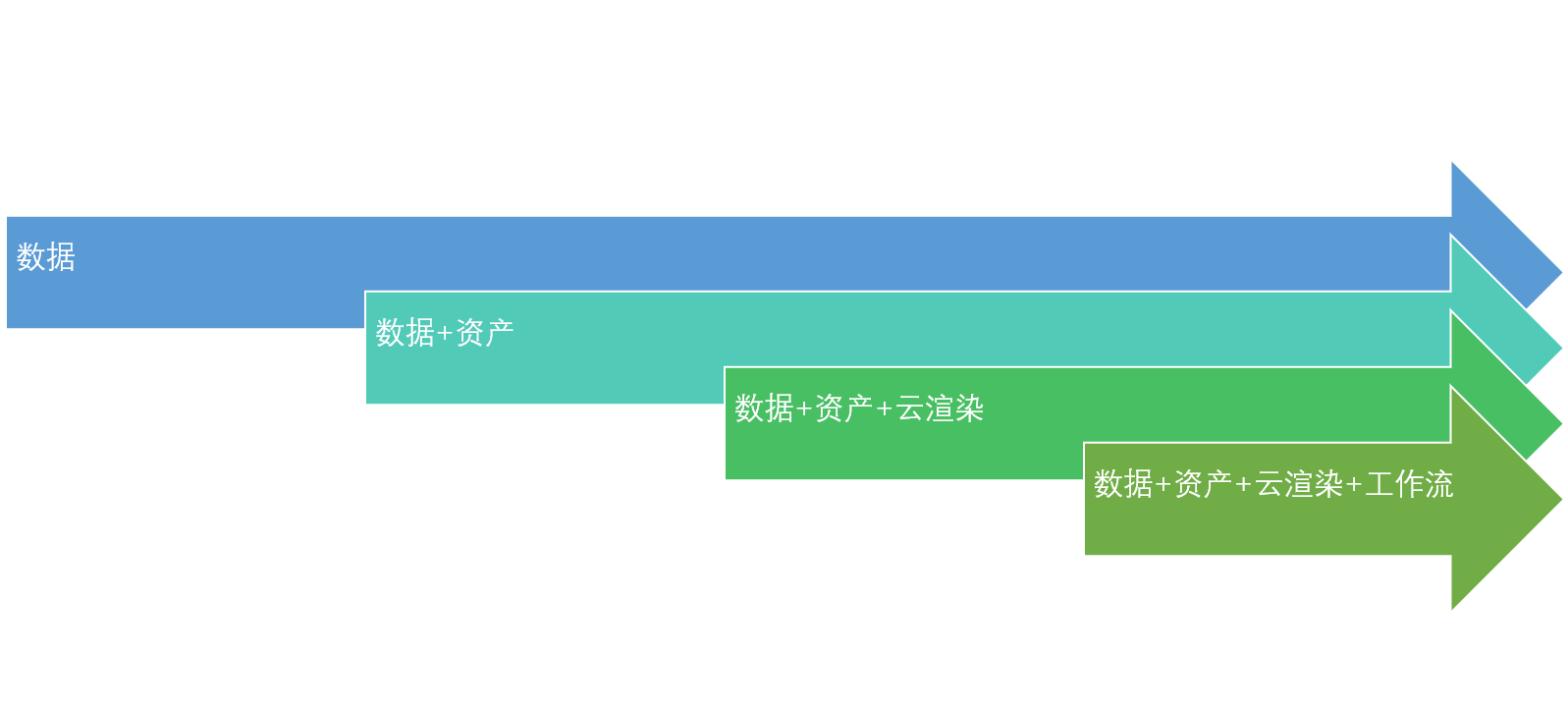 1、动作表情生成数据输出
适用于已有数字人模型的产品,直接管理场景,应用数据,使用Motionverse最核心的能力,获取动作和表情数据。
有播报和问答两个场景,播报是根据输入的内容,进行播报动作、口型和表情,并播放对应语音。问答是根据配置好的问答库,根据输入得到答案,并生成动作、口型和表情,并播放对应答案的语音。
1、动作表情生成数据输出
适用于已有数字人模型的产品,直接管理场景,应用数据,使用Motionverse最核心的能力,获取动作和表情数据。
有播报和问答两个场景,播报是根据输入的内容,进行播报动作、口型和表情,并播放对应语音。问答是根据配置好的问答库,根据输入得到答案,并生成动作、口型和表情,并播放对应答案的语音。
2、数字人模型 + 动作表情生成数据输出 适用于没有自己数字人模型的产品,可以使用Motionverse捏脸工具或者模型库的方式,从Motoinverse的资产中,获取对应的数字人模型,然后再获取对应的驱动数据。 整个模型的驱动数据来自于Motionverse中台,渲染是在本地利用本地自身算力完成。
3、数字人模型 + 动作表情生成数据 + 云渲染输出
适用于本地算力不足,或者显示质量非常高的如超写实角色的使用场景。
在本层次输出中,一方面模型和驱动数据都来源于Motionverse中台,另外一方面,也使用了Motionverse的云渲染能力,利用云端的渲染资源,完成了驱动和渲染所有工作,本地媏直接拉取视频流即可。

4、定制工作流 根据用户需求,完全自定义定制独立的工作流